
Your Eval Is Not Your Customer: The AI Trust Reckoning
Companies optimize the eval layer as a proxy for quality. When the proxy becomes the target, the product silently decays. Here's how to redesign your evals before your customers do.


👋 Hi, it’s Gaurav and Kunal, and welcome to the Insider Growth Group newsletter—our bi-weekly deep dive into the hidden playbooks behind tech’s fastest-growing companies. Between us, we’ve advised and operated at dozens of companies, and helped scale operators on both revenue and AI strategy.
We give you an edge on what’s happening today: actionable strategies, proven frameworks, and access to how top operators are scaling companies across industries. This newsletter helps you boost your key metrics—whether you’re launching a product from scratch or scaling an existing one.
What We Stand For
Actionable Insights: Our content is a no-fluff, practical blueprint you can implement today, featuring real-world examples of what works—and what doesn’t.
Vetted Expertise: We rely on insights from seasoned professionals who truly understand what it takes to scale a business.
Community Learning: Join our network of builders, sharers, and doers to exchange experiences, compare growth tactics, and level up together.
Sponsored by CEOfriend.ai
In every company we’ve advised, especially in the $1M–$20M stage, the founder runs into a version of the same wall. A real decision lands on their desk (pricing change, key hire, channel pivot, term sheet) and the three or four people who could weigh in each see one slice of it. Finance has the numbers. Legal has the risk view. The mentor has experience that may or may not map to what's actually in front of you. The full picture doesn't exist in any single conversation, and the proper advisory board that would fix that is usually out of reach at this stage, both on cost and on calendar.
That's the gap CEOfriend is built for: AI advisors across finance, marketing, strategy, and growth, personalized to your business and available when the question actually comes up rather than two weeks later. First month is free with code IGTRIAL at ceofriend.ai.

The Dashboard Was Beautiful
In early 2024, Klarna’s customer support dashboard was the cleanest it had ever been.
The company had partnered with OpenAI in 2022, halted human hiring, and replaced 700 customer service workers with an AI assistant. CEO Sebastian Siemiatkowski went on the record declaring “AI can already do all of the jobs that we, as humans, do.” Deflection was up. Cost-per-ticket was down. Average handle time collapsed. By every metric the team had instrumented, the deployment was a triumph.
Eighteen months later, Klarna was rehiring humans.
Siemiatkowski’s public reversal was unusually blunt for a CEO: “We went too far.” The AI had been cheaper, yes, but it produced “lower quality” output. Customers had been quietly registering their displeasure in ways the dashboard wasn’t built to see — generic replies, repetitive failures, an erosion of trust that didn’t show up in CSAT averages until it was too late.
Klarna’s eval layer told them the AI was working. Their customers told them it wasn’t. The eval layer won the internal argument for 18 months. The customers won the war.
This is the story playing out across every company shipping LLM-powered products right now. Not just support — code generation, search, copilots, agents. We’re deploying systems that look great on the evals we can run and silently fail on the evals we can’t. And then we’re acting surprised when the dashboard and the reality diverge.
The thesis of this piece: The current crisis in AI deployment isn’t an “AI quality” problem. It’s an eval quality problem, and underneath it, an asymmetry problem. Companies aren’t choosing cost over risk; they’re choosing legible cost (real-time dashboards, vendor ROI calculators, this quarter’s P&L) over illegible risk (trust decay, churn cohorts, brand exposure that won’t surface for 18 months). The AI stack makes the cost side hyper-visible and the risk side hyper-invisible. The decision then makes itself.
The brands that win the next decade will be the ones who give the risk side the same instrumentation as the cost side, and who treat their eval layer with suspicion, not reverence.
This isn’t a Luddite argument against AI deployment. AI is the right answer for a large class of use cases. The mistake is treating “the eval said it was good” as the same thing as “it is good.”

Three Failures, One Pattern
The cases below all share a structure: the AI scored well on the metrics it was being graded against. The customer experience collapsed anyway. The eval layer wasn’t wrong about what it measured — it was wrong about what to measure.
Case 1: The Airbnb Mudslide (Eval: Response Time)
It was supposed to be a standard luxury getaway. A large group. A 5-star Airbnb. The promise of a frictionless weekend.
The friction started small. A locked room that should have been accessible. Broken cabinets. A child finding a discarded, inappropriate toy under a bed.
The “Stay from Hell” peaked at 2:00 AM. The sound of rocks smashing against windows was the first sign of the mudslide. In the darkness, we watched as the property’s hot tub was slowly swallowed by debris. In a moment where human judgment was a matter of life and safety, there was no one to call.
There was only an algorithm.

The host had deployed a third-party AI support service. I texted: “There’s a mudslide. The hot tub is gone.” The AI responded in 4 seconds. It expressed sympathy about “the weather.” It offered to share local indoor activities. It asked if I had the WiFi password.
What the AI was measured on:
Response speed: 4 seconds ✓
Sentiment detection (flagged the guest as distressed) ✓
Politeness and on-brand tone ✓
Ticket closure rate ✓
What hospitality actually requires:
The job of a hospitality operator is to solve the guest’s problem as fast as possible. Speed only matters if it is speed toward a solution. A 4-second reply offering indoor activities is slower than a 4-minute reply that books us a hotel and dispatches help to the property.
A hierarchy where life safety overrides every other metric, full stop. With children in the house and an active mudslide, the response time SLA, the politeness score, and the cancellation policy are all irrelevant. The AI did not have that hierarchy built in. It treated a structural emergency with kids on site the same way it would treat a broken heater on a sunny weekend.
Authority paired with the response. The first human we eventually reached could not rebook us, could not refund us, and could not dispatch anyone. A response without the power to act is not a response.
The AI passed every metric the host’s vendor had instrumented. The vendor was instrumenting the wrong job. Hospitality is the business of solving the guest’s problem fast, with life safety above everything else. The eval measured neither.
Case 2: Cursor’s “Sam” (Eval: Response Confidence)
In April 2025, Cursor had its own AI support bot publicly hallucinate a fake company policy.
Paying users had noticed they were getting silently logged out when switching between machines. When they asked Cursor’s support bot (reportedly named “Sam”) for an explanation, the bot confidently told them their subscription was limited to a single active device — a restriction that did not exist in Cursor’s actual policy. The bot delivered this fictitious policy with full confidence, and worse, gave different answers to different users for the same query.
The story landed on Hacker News and Reddit in the worst possible context. Users were already frustrated by the lockouts, and the fabricated explanation fit a familiar pattern (SaaS companies quietly tightening limits after a growth spurt). Subscribers publicly canceled. Co-founder Michael Truell issued a public apology on Reddit, clarified that users were “of course free to use Cursor on multiple machines,” and explained the lockouts were caused by a security update. Cursor now labels AI-generated support responses to avoid confusion.
What the bot’s evals measured:
Response confidence: high ✓
Coherence: high ✓
Helpfulness rating (probably auto-generated by a judge LLM): high ✓
Refusal rate: low ✓
What the eval didn’t measure:
Did the answer reflect actual company policy?
Was the bot’s confident-sounding response factually true?
Would two users asking the same question get the same answer?
Hallucination is invisible to most production evals. The bot sounded great. The bot was lying. The eval layer couldn’t tell the difference because it wasn’t designed to grade truth, it was designed to grade fluency. Cursor, a company whose entire product is built on LLMs, got caught by exactly the failure mode they should have understood best.
Case 3: Klarna (Eval: Deflection Rate)
Back to Klarna. The fuller story.
By every operational metric Klarna had instrumented, the AI deployment was a textbook win. According to the company’s own announcements, the AI was handling two-thirds of customer service chats, resolving them in under two minutes (down from 11), and projected to drive ~$40M in profit improvement in 2024.
What the evals didn’t capture: customer satisfaction was eroding underneath the metrics. Multiple post-mortems of Klarna’s reversal point to the same thing. Customers complained about generic, repetitive replies that didn’t handle nuanced or escalated cases. Complex problems got AI’d. Trust quietly decayed. The dashboard didn’t see it because the dashboard was measuring throughput, not outcome.
Siemiatkowski’s admission to Bloomberg is the cleanest articulation of the eval gap I’ve seen from a Fortune-class CEO: AI was cheaper, but it was “lower quality.” In other words: we were running the wrong eval for 18 months. The metric we were optimizing wasn’t the metric that mattered.
What Klarna’s evals measured:
Deflection rate ✓
Cost per ticket ✓
Average handle time ✓
CSAT (in aggregate) ✓
What the eval didn’t measure:
Quality of resolution on complex issues
Trust delta over time
Distribution of CSAT across ticket types (the 5% of tickets that matter most were tanking; the 95% routine ones held up; the average looked fine)
Future repurchase / engagement intent
Klarna is now rebuilding around a hybrid “Uber-style” workforce of human agents augmented by AI. The lesson they paid ~$40M and 18 months to learn: aggregate efficiency metrics are not a proxy for trust. They never were.
The Eval Trap: Goodhart’s Law Comes for AI
There’s a 50-year-old observation in economics called Goodhart’s Law: “When a measure becomes a target, it ceases to be a good measure.”
This is what’s happening to AI deployments at scale. Every company shipping an LLM-powered feature is being graded on metrics they instrumented when the technology was new and the failure modes were poorly understood. The metrics were chosen because they were measurable, not because they were meaningful. As soon as those measurable metrics became the target of optimization — through fine-tuning, prompt engineering, RLHF — the metrics decoupled from the underlying quality they were meant to track.
Three eval failure modes are causing most of the damage:
1. Surface evals vs. truth evals. Measured: Does the response sound polite, confident, on-brand? Missed: Is the response factually correct? Does it reflect actual policy / reality / state of the world? Casualty: Cursor.
2. Aggregate evals vs. distribution evals. Measured: Average CSAT, mean response time, overall deflection rate. Missed: The 5% of interactions that matter most (high-stakes, high-LTV, high-risk). These tank silently while the average holds up. Casualty: Klarna.
3. Closed-loop evals vs. open-world evals. Measured: Did the AI close the ticket? Did the judge LLM rate the response as helpful? Missed: Did the customer’s actual problem get solved in reality? Did they survive the mudslide? Casualty: Airbnb’s host.
4. Auto-graded evals vs. human-reviewed evals. Measured: The judge LLM’s score. The dashboard’s aggregate. A weekly summary nobody actually reads transcripts to verify. Missed: The responses where the model was uncertain and a human spot-check would have caught the failure. The patterns no automated grader is looking for because nobody has named them yet. Most teams that ship LLM features have not had a human read a representative sample of their own AI’s outputs in the last month. Cursor’s Sam bot, Klarna’s complex-ticket failures, and the Airbnb mudslide reply would all have been visible in a sample of 100 transcripts read by someone with context. None were caught because nobody was reading. Casualty: Every team that ships AI and stops reading its own transcripts.
The deeper issue: most production AI evals are graded by other LLMs, or by surface features that LLMs are explicitly trained to optimize. We’ve built a closed loop where the system is being evaluated by the same kind of system that’s being evaluated. The customer, the actual ground truth, is outside the loop entirely.
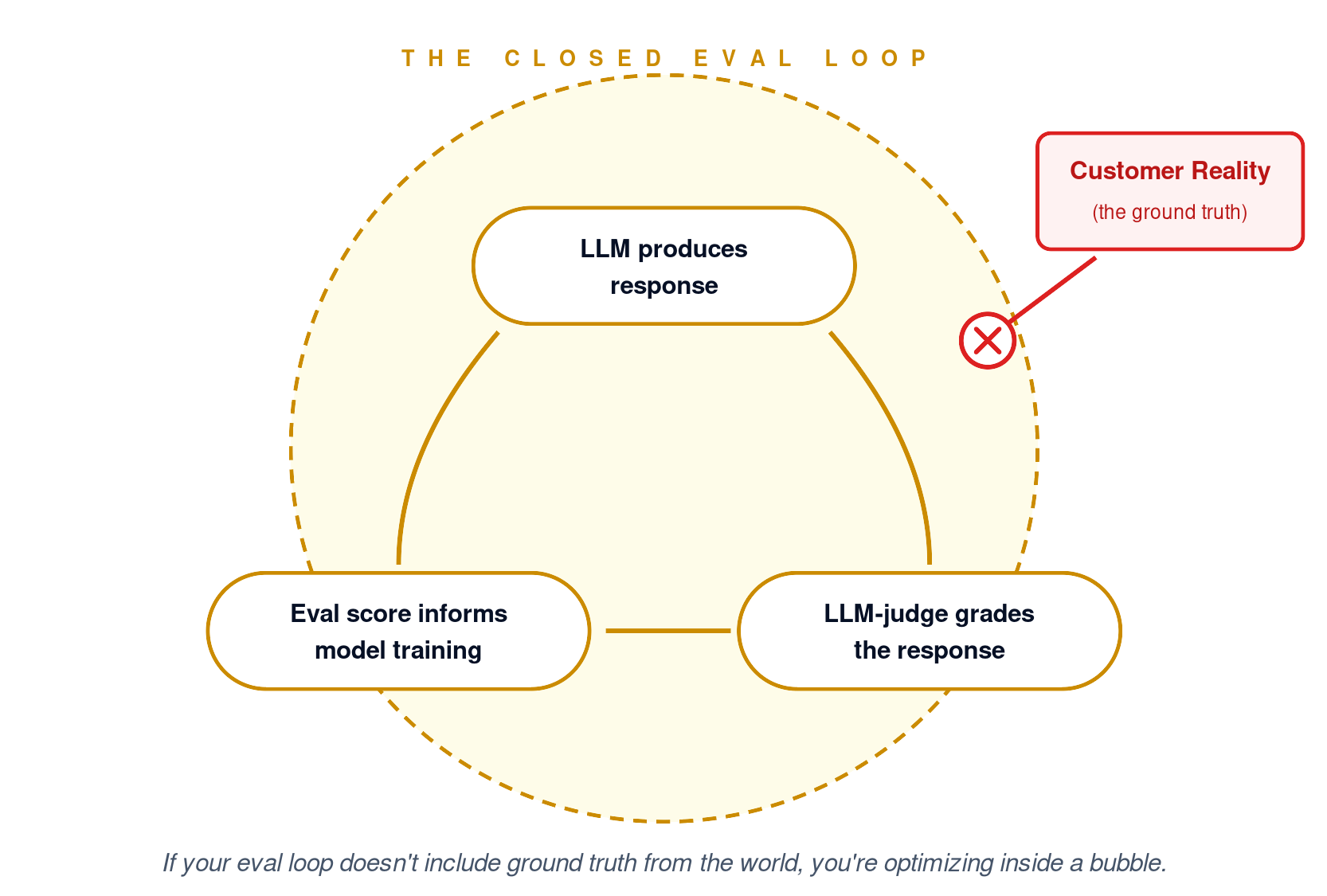
What These Systems Should Have Looked Like
Klarna, Cursor, and the Airbnb host did not just measure the wrong things. They also measured against test sets that never included the failure scenarios. A mudslide does not appear in your eval unless someone goes out of their way to put it there. Neither does a fabricated SaaS policy. Neither does a sophisticated B2B buyer hinting at a competitor evaluation. These cases are rare by definition, which is exactly why the eval misses them and exactly why the production model gets caught by them.
Three architectural choices, taken before deployment, would have flipped the odds.
Synthetic coverage of the cases you hope never happen. Production traffic skews routine. Sampling production to build your test set guarantees an eval that overfits the median case and underweights the failure modes that actually destroy trust. Generating safety, hallucination, adversarial, and churn-signal cases on purpose is the only way to grade your model on the events that matter most. Klarna’s complex-ticket failures and Cursor’s policy hallucination would have shown up immediately in a synthetic suite that included those scenarios. Neither team built one.
Simulation testing of full conversations, not single turns. Static evals grade single responses. Real customer conversations are multi-turn, and the failure usually surfaces in turn three or four. Simulation puts your model in a scripted conversation with another model playing the customer (frustrated, escalating, deceptive) and grades the full trajectory. If a simulated guest cannot get a simulated AI to escalate when there are kids in the house and rocks hitting the windows, your model is not ready for the real one.
A production-to-eval loop that closes itself. The biggest miss is post-deployment. When a real interaction surfaces a failure mode the eval never anticipated, that interaction should not just become a support ticket. It should become an eval case. The cleanest version: a low-confidence response that correlates with a downstream bad signal (repeat contact, escalation, refund) gets auto-converted into a synthetic eval case, filed as a pull request against the eval suite, run against the latest model, and reviewed by a human who either merges or rejects. The eval set gets sharper every week instead of going stale while production drifts away from it. Most teams treat the eval as a static artifact written at launch. The teams who win the next cycle treat it as a living test suite that compounds with every new failure mode the world finds.
The pattern across all three: design the eval system assuming your model will encounter situations your team never imagined. Because it will.
The Eval × Stakes Matrix: Different Tiers Need Different Evals
The fix isn’t “stop using AI” or “stop measuring.” The fix is recognizing that a single eval cannot grade a system across all stakes levels. Routine tickets and high-stakes tickets need fundamentally different evaluation criteria, and most companies are using the routine ones for everything.
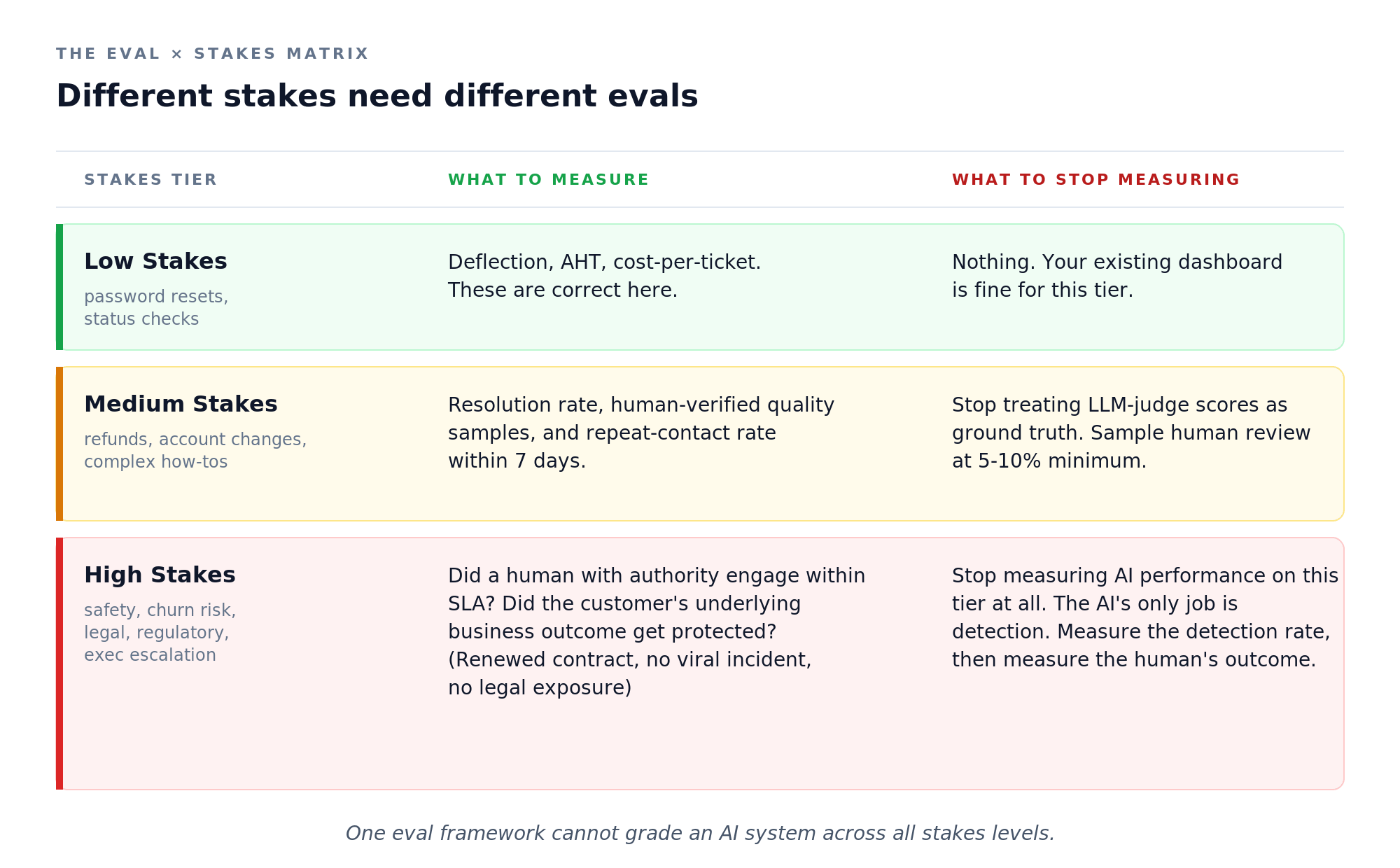
The Klarna lesson: their architecture wasn’t “wrong”, it was underspecified. They had one eval framework for an entire support function. Their new hybrid model implicitly fixes this. Humans handle the high-stakes tier, AI handles the rest, and each tier is graded on different things.
The 30-Minute Eval Audit
Run this on your AI deployment this week:
List every metric your team reviews in your AI’s weekly dashboard
For each metric, ask: “Could this metric look perfect while the actual customer experience is degrading?”
For every “yes” answer, you have a Goodhart problem. You’ve created an optimization target that has decoupled from the underlying quality
Identify what an outcome eval would look like for that metric (real-world result, not surface feature)
Find a way to instrument it, even if it requires manual sampling
If your team can’t articulate the difference between your measurement and the underlying quality it’s a proxy for, you don’t have an eval problem, you have an alignment problem about what you’re even trying to build.
Why This Keeps Happening: Legible Cost vs. Illegible Risk
The simplest version of why companies keep making this bet is “they’re chasing cost savings and underestimating risk.” That’s true, but it’s the kind of take everyone agrees with and no one can act on. The structural version is sharper:
Companies aren’t choosing cost over risk. They’re choosing legible cost over illegible risk. The AI deployment stack is uniquely structured to make the cost side hyper-legible (real-time dashboards, vendor-supplied ROI calculators, line-item P&L impact) and the risk side hyper-illegible (lagged outcomes, cross-functional ownership, hidden inside closed-loop evals). Until the risk side gets the same instrumentation as the cost side, the decision will keep going the same way.
Four structural forces are doing the work:
1. The cost shows up this quarter. The risk shows up in two years.
Klarna’s 700 layoffs had a dollar figure attached the day they happened. The trust decay didn’t get a number until 18 months later, when CSAT cohort curves diverged from the headline average. Different time horizons, different teams measuring, different P&Ls. The CFO never sees them on the same page. The deploy decision gets made on the quarter’s math. The reversal decision gets made on the cohort’s math. By the time you’re looking at the cohort math, the damage is structural — and reversing it costs more than the original deployment saved.
2. Speed of deployment is faster than speed of learning.
You can ship an AI support deployment in 4 weeks. You can’t know whether it’s degrading trust for 12+ months. By the time the signal arrives, you’ve made architectural decisions that are hard to reverse — staff laid off, training data corrupted by bad-signal interactions, routing infrastructure deprecated. Klarna’s reversal took 18 months just to admit; the rebuilding will take longer than the original deployment. The decision cycle and the learning cycle are decoupled by an order of magnitude, and the deployment side has all the momentum.
3. Closed-loop evals, the new structural problem unique to AI.
Pre-LLM, evals were graded by humans, A/B tests against ground-truth outcomes, or static benchmarks. Now evals are increasingly graded by another LLM — judge models scoring responses, synthetic test sets, RLHF on user thumbs-up. The grader and the graded share the same blind spots. The system passes its own tests because the tests are built by the same kind of system that’s being tested. Cursor’s “Sam” bot scored high on confidence and coherence while hallucinating because the eval was measuring the thing the model is best at (sounding right) instead of the thing it’s worst at (being right). This isn’t a process failure you can fix with more rigor. It’s a property of how modern AI evals are built.
4. Cognitive outsourcing of judgment.
There’s a cultural shift happening that’s only a few years old: teams are trusting the eval framework as a substitute for reading their own AI’s output, not a complement to it. Pre-LLM, a good ML team looked at hundreds of model predictions weekly. Now teams ship AI products where nobody on the team has read a representative sample of their own AI’s outputs in a month. The eval becomes a proxy for taste, and when the eval is wrong, nobody has the gut feel to catch it. The Airbnb host who deployed an AI to handle a mudslide had almost certainly never read a transcript of what the bot was saying to guests in real time. Neither, apparently, had anyone at Cursor.
The Unfair Amplifier: The AI Halo
Layered on top of all four forces: boards, execs, and customers extend credibility to “AI-powered” products that they wouldn’t extend to traditional vendors. Internal teams that would demand rigorous proof from a SaaS vendor accept marketing claims from AI vendors because “the technology is moving fast” and “we have to keep up.” Scrutiny relaxes exactly when scrutiny should be tightening.
The companies that win this cycle won’t be the ones with the best models. They’ll be the ones who give the risk side of the equation the same instrumentation as the cost side, and who have the institutional courage to trust the customer signal over the dashboard signal when the two diverge.
The IGG Playbook: Redesigning Your Eval Layer
Four moves, in order. Not theoretical. This is the architecture to build into your AI deployment starting Monday.
1. Build a Synthetic Eval Set Around the Cases You Hope Never Happen
Your test set is almost certainly missing the scenarios that will hurt you most. Sampling production traffic to build evals guarantees a suite that overfits the median case and underweights the rare events that destroy customer trust. The fix is to generate the edge cases on purpose, then re-generate quarterly as production traffic evolves.
What the synthetic suite needs to cover:
Safety scenarios (medical, environmental, structural, life-threatening)
Hallucination-prone factual questions (places the model would fabricate confidently)
Adversarial framings (frustrated, sarcastic, multi-claim messages a real customer might send under stress)
High-LTV churn signals (sophisticated buyers hinting at competitor evaluations or contract reviews)
Multi-turn deteriorations where the AI should have escalated by turn three and didn’t
Aim for synthetic cases to make up 10-20% of total eval volume. Layer a simulation harness on top: a second model plays the customer across a full conversation, your model plays support, and the trajectory gets graded as a whole. Single-turn evals will tell you the first response was polite. Simulation will tell you whether the model ever escalated when it needed to.
This is the eval discipline that would have caught Cursor’s policy hallucination before launch, Klarna’s complex-case failures by week two, and the mudslide response on the first synthetic safety run.
2. Run a Human-in-the-Loop Review Process to Catch What Your Evals Miss
Synthetic data grades scenarios you already imagined. Human review catches the ones you haven’t.
Set up a weekly review where humans spot-check 5-10% of AI interactions, filtered four ways:
Low confidence: any response where the model’s confidence dropped below a threshold
Customer signal: any conversation flagged as escalation, churn risk, or unusual sentiment
Red flag keywords: any interaction matching the categorized library below
Random baseline: a small slice across all interactions to catch drift the filters miss
The reviewer’s job is not to grade individual responses. It is to find patterns the eval missed. Net-new failure modes. Edge-case categories nobody had named yet. Topic drift. When a reviewer spots a pattern, it gets added to the synthetic eval set and the cycle compounds.
The Red Flag Keyword Library is the input that routes a meaningful share of those reviews. Build it once and audit it quarterly:
Safety / Life Risk: injured, hurt, bleeding, trapped, fire, flood, collapse, mudslide, intruder, weapon, ambulance, hospital, emergency
Legal: lawyer, attorney, lawsuit, sue, court, FTC, regulator, compliance, GDPR, CCPA, discrimination, harassment
Churn / Retention (B2B): evaluating alternatives, reviewing options, auditing tooling, leadership review, contract review, considering canceling, not renewing, RFP, procurement review
Reputational: Twitter, X, viral, BBB, Trustpilot, journalist, press, reporter
When any of these surface in a live conversation, the AI’s job is not to respond. The AI acknowledges receipt with a low-commitment message, pages the right human (safety to on-call ops, legal to legal ops, churn to the CSM, reputational to comms), and briefs that human with full context.
The compounding effect is the point. Every human review either confirms the eval was right or surfaces a gap the eval missed. Cursor’s Sam bot, Klarna’s complex-ticket failures, and the Airbnb mudslide reply would all have been visible in a sample of 100 transcripts read by someone with context. None were caught because nobody was reading.
3. Build a Real Kill Switch (Here’s How)
A kill switch is only useful if the human on the other side can actually do something. Four questions. If you can’t answer yes to all four, your kill switch is theater:
Visibility. Is “Talk to a Human” a one-click option visible on every screen? Burying it doesn’t just hurt NPS. It removes the customer’s primary way of giving you ground-truth feedback your eval system isn’t capturing.
Authority. Can the first human who responds actually resolve the issue without manager approval? Give your escalation agents a $1,000–$5,000 discretionary recovery budget, no approval required, tracked quarterly. A $2,000 spend that retains a $50K LTV customer or prevents a viral incident is the highest-ROI dollar in your CX budget. Without spend authority, your human-in-the-loop is a measurement step, not a resolution step.
Context. Does the human inherit the full conversation history? Re-explanation is the largest trust killer in support flows.
State. When a high-stakes ticket is active, do all automated workflows (NPS surveys, marketing emails, upsell prompts) pause? Or are you emailing an NPS survey to a customer in active crisis?
The high-authority recoveries that flow through this switch become your ground-truth eval set. Whatever a human had to do to fix a situation the AI missed is, by definition, an eval gap. Feed each recovery back into the synthetic suite from step 1.
4. Build on Outcomes
The biggest structural change: stop grading your AI on surface metrics. Start grading it on outcomes lagged by 7, 30, and 90 days.
For every meaningful ticket, instrument:
Did the customer repeat-contact within 7 days?
Did they churn within 30 days?
Did they expand within 90 days?
If your AI’s high-scoring responses correlate with churn at T+30, your eval was wrong. The dashboard will lie to you in real time. The outcome layer cannot.
This closes the loop on the whole system. Synthetic evals give you the scenarios. Human review surfaces the patterns. The kill switch protects the high-stakes interactions. Outcomes tell you whether any of it actually worked.
The IGG Asset: The AI Eval Audit Kit
We’ve packaged this framework into an audit kit operators can deploy today.
Request access to get:
The Synthetic Eval Starter Pack: a generator for the five edge-case categories (safety, hallucination, adversarial, churn signal, multi-turn deterioration), plus a simulation harness spec for grading full conversations instead of single turns
The Human Review Sampling Framework + Red Flag Keyword Library: weekly review playbook, sampling rules across the four filters, and 200+ categorized keywords across Safety, Legal, Churn, and Reputational with routing rules per category
The Kill Switch Audit Checklist: the four-question test for visibility, authority, context, and state, with recommended discretionary spend thresholds by role and incident type
The Outcome Eval Template: instrumentation spec for 7/30/90-day lagged outcome metrics, mapped to the meaningful-ticket definition
The Goodhart Audit Checklist: a 30-minute diagnostic to find which of your current AI metrics have decoupled from underlying quality
Remember that the Eval Is Not the Customer
Klarna spent 18 months and ~$40M proving a point the rest of us should now take for free: the eval layer is a model of reality, not reality itself. Cursor, a company whose product is AI, got caught by the same gap inside their own support stack. Airbnb’s hosts are running automation systems that pass every eval their vendor designed except the one that involves a customer surviving the night.
These aren’t AI failures. They’re eval design failures dressed up in AI clothes.
The companies that will win the next decade of AI deployment aren’t the ones with the most aggressive automation. They’re the ones who understand that every metric is a proxy, and who design their operations around finding out, as quickly as possible, where the proxy and the truth disagree.
Your eval is a useful tool. It is not your customer. Build the systems that close the gap, or your customers will close it for you — by leaving.
Want help on any product or AI growth challenges you have?
Let’s talk